Translation Mining for the perfect
The technique of Translation Mining requires sentence-aligned multilingual corpora. The steps it involves for the perfect are briefly presented here. A pictorial representation is given in Figure 1:
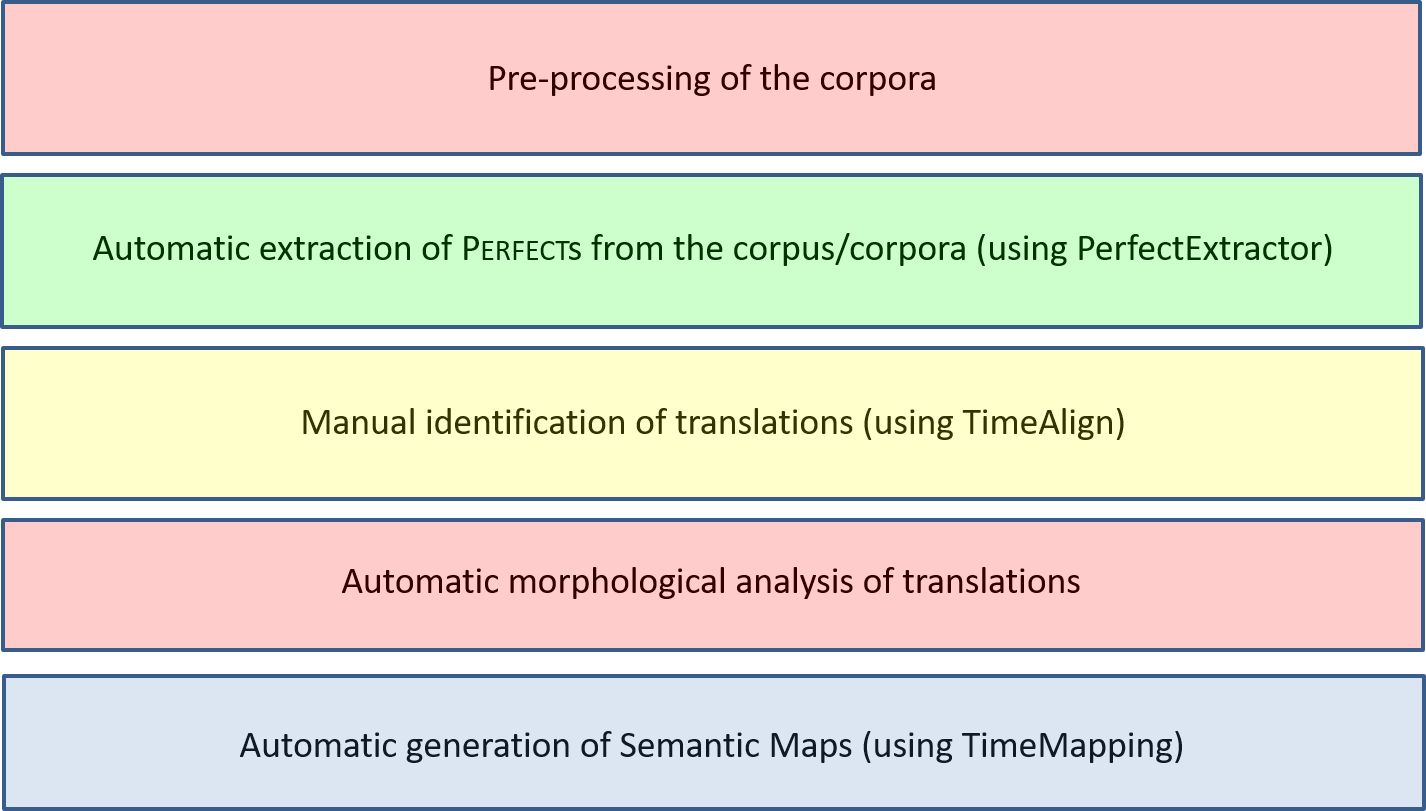
Figure 1: The steps involved in Translation Mining for the perfect
Step 1
As with all corpus-based research, the techniques we use come with certain requirements on the corpora and – wherever relevant – some preprocessing (lemmatization, POS-tagging, etc.) might be required.
Step 2
In the second step we need language-specific algorithms that allow us to automatically extract Perfects. We have developed these algorithms for five languages up till now (English, French, Dutch, German and Spanish). They go under the name PerfectExtractor and the code is freely available through this website.
Step 3
Step 3 is a manual step in which the perfects we have extracted are matched with their counterparts in the other languages of the sample. To limit the effort of the human annotator we designed TimeAlign, a piece of web-based software that limits the work of the annotator to simply clicking on the relevant words in the translation. Figure 2 presents the user-friendly interface. A tutorial and the code are freely available through this website.
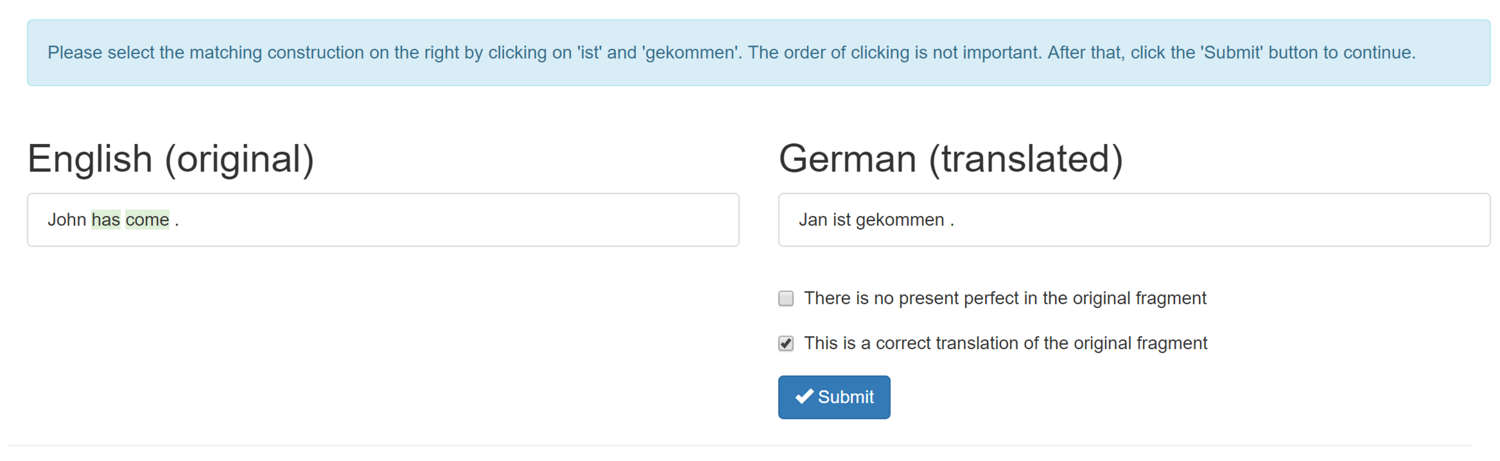
Figure 2: the TimeAlign interface
Step 4
After the translations have been identified we analyze the tenses that are used. We are currently using existing morphological taggers and writing small extensions to them to approximate a correct tense analysis. This is however work in progress and the data we are currently working with might still present some tagging problems. In particular we are aware of the fact that our morphological tags are insensitive to morphological ambiguity (e.g. Spanish votamos can be both a present tense and a past tense) and that not all passives are correctly analyzed in the different languages.
Step 5
We refer to the final step as TimeMapping. It involves using the output of steps 2 to 4 to make a table in which every Perfect extracted in Step 2 is matched with the tenses of its translations obtained in Steps 3 and 4. This leads – for a sample of five languages – to five-tuples like the following:
<Präteritum,Simple_Past,Passé_Composé,Pretérito_Perfecto_Compuesto,Voltooid_Tegenwoordige_Tijd>
These five-tuples are the input for an algorithm that calculates the distance between pairs of five-tuples based on their variation in tense use. The output of this algorithm is then two-dimensionally represented in ‘Semantic Maps’ like the following:
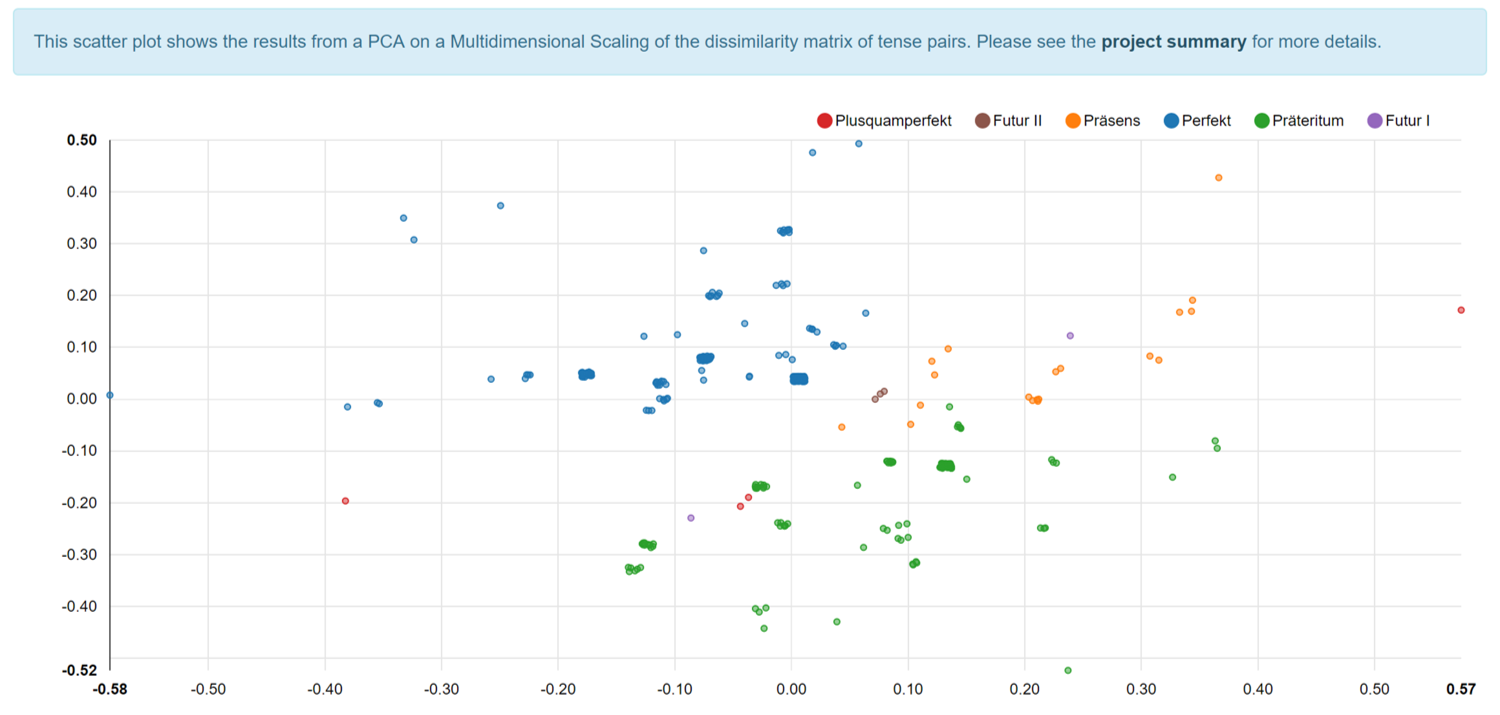
Figure 3: the output of TimeMapping
The different points represent the different five-tuples and the distance between them is based on the variation in tense use they exhibit. In Figure 3 we have highlighted the German tense forms but the same map is available with highlighting of the English, Dutch, Spanish and French tense forms. Hovering over the points immediately shows the five-tuple. Clicking on the points leads to the corpus contexts the five-tuples represent. This is illustrated in Figure 4.
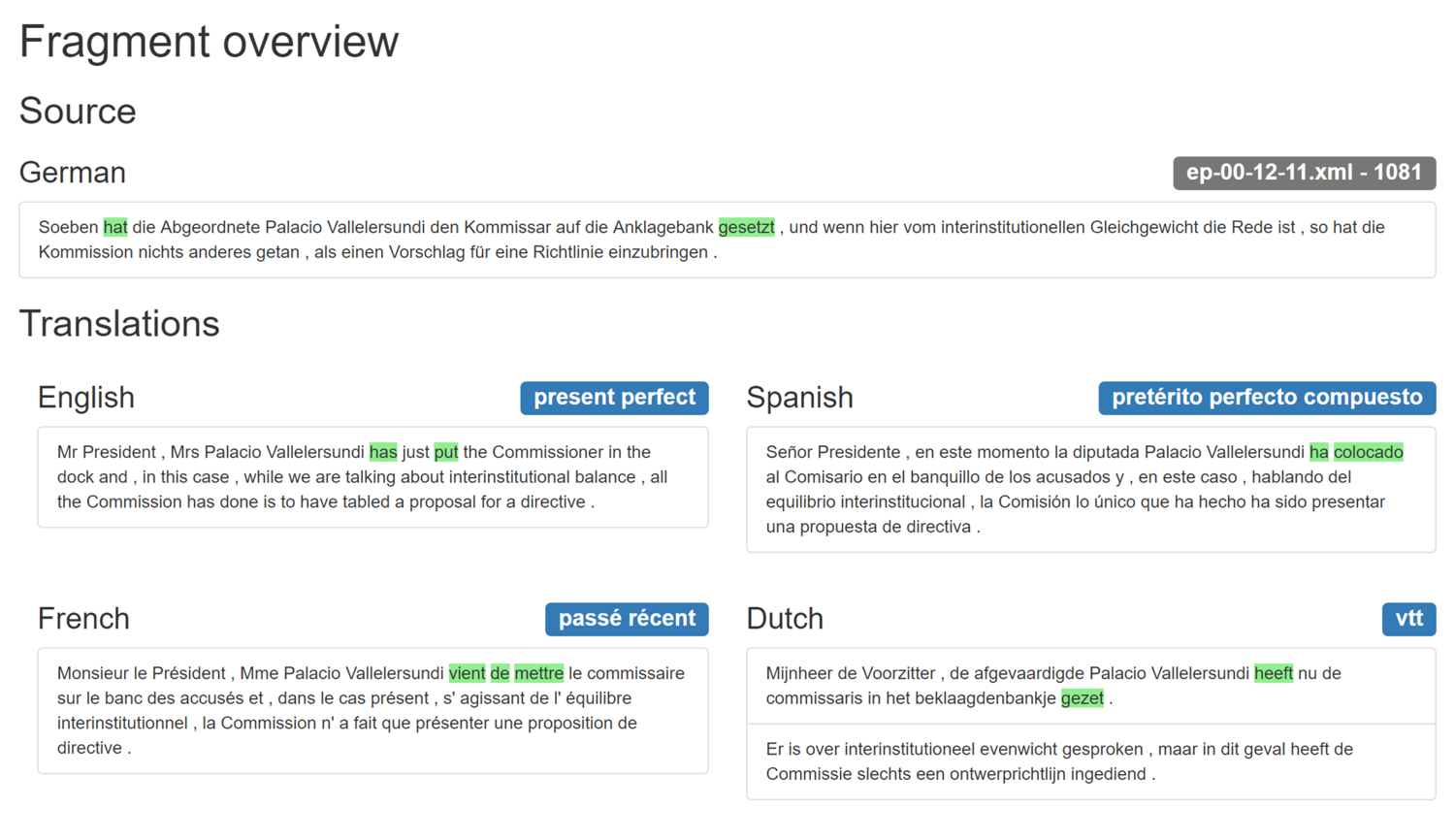
Figure 4: Data linked to the points on the Semantic Map
The codes underlying TimeMapping and TimeAlign are currently merged and are made available through this website. The maps are currently only available after login.